使用状态
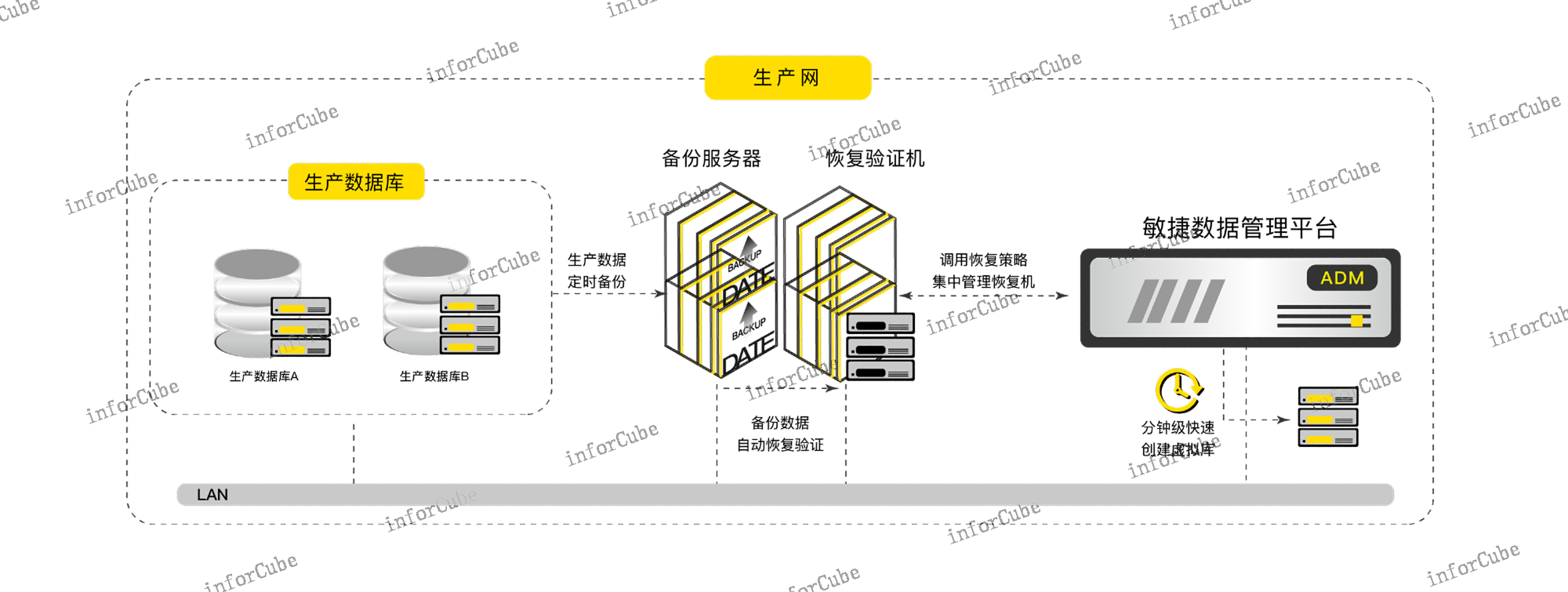
通过敏捷数据管理平台ADM产品的部署实施,采用数据库虚拟化技术,快速将数据交付到开发、测试网,有效减少开发、测试场景中测试数据的准备时间,提高了开发、测试环境搭建的效率。ADM内置独有的高效压缩存储池,平均压缩比3:1,存储即压缩,降低了基础数据源获取的存储成本,只需一份基础数据源,即可快速拉起多份虚拟数据库,节约了存储成本10倍以上。ADM通过虚拟数据库快照功能,可以灵活地对虚拟数据库的状态进行管理和维护。使用人员可以随时保存当前的数据库使用状态,用于开发、测试的数据版本迭代。上讯ADM通过数据备份后获取到的黄金副本开启数据开发利用的创新流程,充分发挥数字资产价值。使用状态
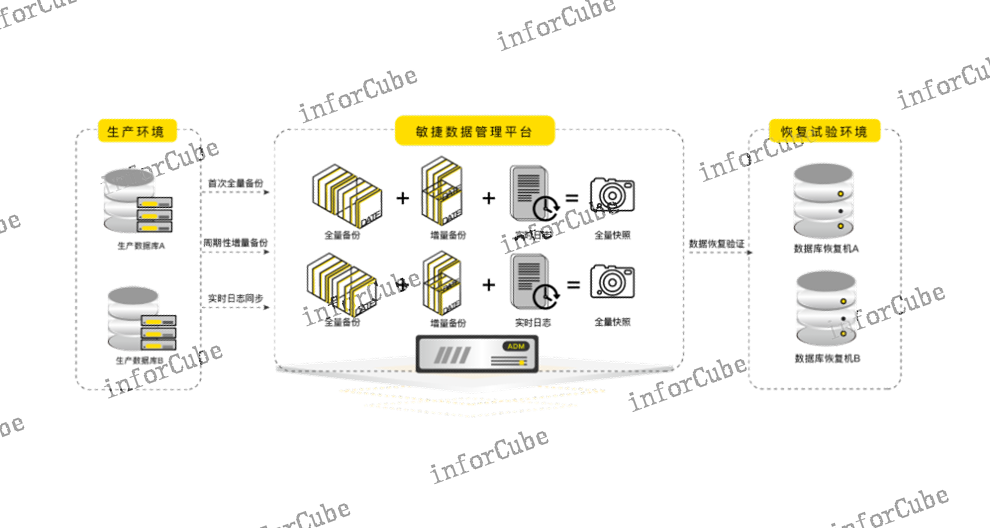
上讯敏捷数据管理平台(ADM)支持增量备份与全量快照合成技术,传统的备份方案大多采用周期性的“全量备份+增量备份”策略,其增量备份大多不可持续,经过一段时间就必须执行一次全量备份。因而传统的备份方案经常面临备份窗口过大的问题,而且其增量备份数据的恢复效率相对低下,因为每个时间点的恢复都依赖于上一次全备副本和上一次全备副本后的所有增量数据,恢复操作需要进行逐个迭代恢复。此外,过期增量数据的清理操作也受限于备份副本之间的依赖关系,不一定能及时被清理。而增量备份与全量快照合成技术,即首先执行全量备份,之后只对新增或改动过的数据进行增量备份,此增量备份数据是持续的,而且每个增量备份的数据副本将自动合成为全量快照副本,便于恢复。因此,增量备份与全量快照合成技术能够大幅度减少备份时间,节省备份数据所需的存储空间,且提升了恢复效率。备份策略名称上讯ADM产品通过虚拟数据秒级分发功能实现测试数据的同时在线交付,缩短了数据交付的时间。
上讯敏捷数据管理平台(ADM)数据异地容灾主要解决本地数据同步到异地,实现异地数据保护的目标。通过制定容灾策略将本地ADM中的数据同步到异地ADM中,容灾的数据类型包括存储池中的全部备份数据和虚拟副本数据,容灾类型支持实时容灾和定时容灾,根据生产数据的容灾需求制定合理的容灾策略,保证为生产数据提供双重保护。当本地生产数据或备份数据丢失、损坏时,立即启用容灾端接管业务,备份策略自动注册到容灾端管理控制中心(Master),自动接管备份任务,保证备份任务的持续不间断运行。
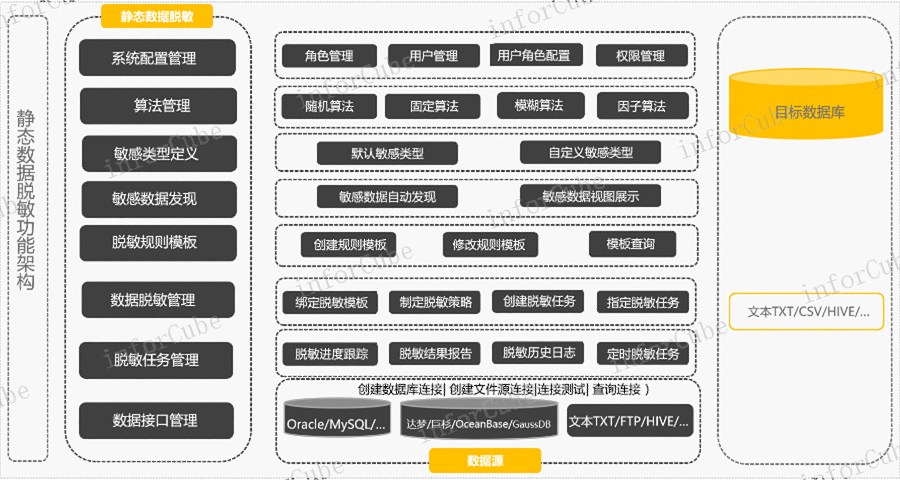
在典型的重复数据删除技术中,根据不同的数据备份场景选择适合的重删策略与粒度方案。在确定重删策略与粒度后,会根据输入侧不同粒度(卷级、文件级、块级)的数据采取不同的数据切分策略,并依据任务级与全局指纹库提供自适应源端的全局重删算法与策略,当前支持源端块级、文件级重删和并行重删技术。源端重删是采用基于内容的可变长数据切分算法,通过对数据块进行哈希算法的***标记,即指纹(Fingerprint),在指纹库中寻找相同的指纹。如果存在相同指纹,则表示已保存了相同的数据块,ADM则不再保存此数据块,而是引用已存在的数据块,从而节省更多的备份空间。该算法还可以智能识别已修改的数据和未修改的数据,从而避免因修改数据位移而导致的未修改数据切分到新数据块中的问题,比较大限度地提升重删性能和重删率,为避免数据备份过程中冗余网络传输与存储开销,在源端设置粗粒度前置数据校验可以明显缩小备份传输过程中的数据冗余,目的在于不备份任意一个冗余数据。市面上的敏感数据管理产品有哪些?
通过网络远程挂载的方式,ADM将TB量级数据拉起时间控制在分钟级,数据恢复的响应速度极快,有效满足开发测试、查询分析、合规审计、应急恢复等场景对数据交付效率的要求。数据库虚拟化技术可延伸应用到文件、虚拟机的副本创建,其优势在于多份虚拟数据副本之间的读写操作单独,完全满足测试环境多场景同步测试的需求,ADM内置的智能读写缓存机制,能够满足压力测试的性能要求;高效的数据副本管理功能,通过可视化的虚拟数据副本拓扑结构图可对系统全局数据使用关系进行预览,有助于完善测试数据的组织关系,优化测试数据的资源分配,同时,通过对拓扑结构的定位点击可自动跳转到相关数据副本的管理页面并检索出对应条目。上讯ADM产品的可管理性体现在数据从上游到下游获取、传输、流转的集中式管理,同时可进行版本管理。系统锁定设置
CDM主要应用于金融、运营商、能源、交通、卫生、事业单位等行业。使用状态
上讯敏捷数据管理平台(ADM)的主要技术是(1)ADM内置独有的高效压缩存储池,压缩比高达3:1,存储即压缩,降低了基础数据源获取的存储成本与持续增长的副本数据存储成本。(2)ADM的数据库虚拟化技术,是通过获取一份基础数据源,快速拉起多份虚拟数据库挂载给目标业务使用,虚拟数据库拉起时几乎不占用物理存储空间,在实验室测试环境下拉起一个10TB数据量的虚拟数据库,只占用1GB左右的存储空间,明显节约了存储成本和时间周期,因此针对开发测试场景,需要对同一份数据创建N份副本数据时,存储成本节约近乎N倍。使用状态
上一篇: 国际上讯数据网关热线
下一篇: 结果打标与管理