目标机
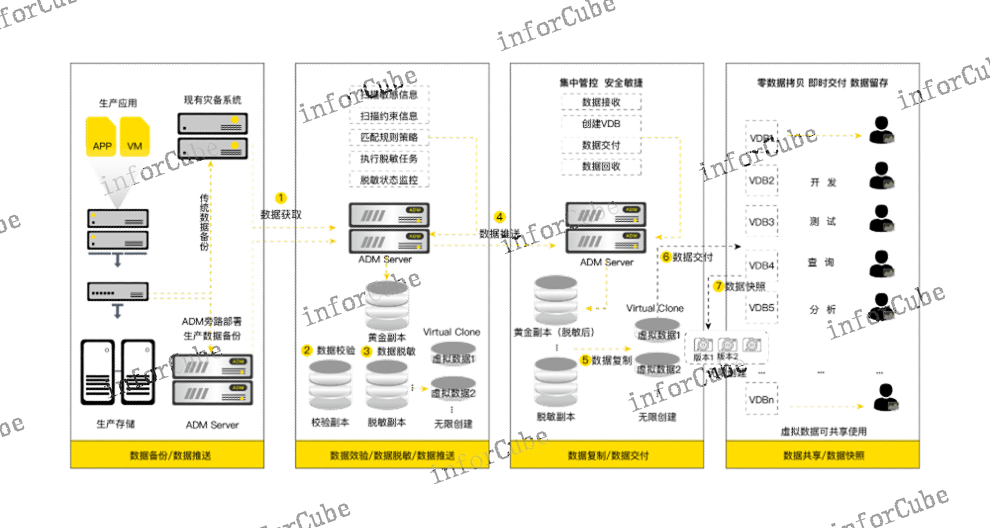
敏感数据处理是上讯敏捷数据管理平台(ADM)产品功能模块之一,主要针对敏感数据的处理使用,提供集敏感数据自动识别、仿真处理与数据交付为一体的敏感数据管理功能,覆盖了敏感数据使用与管理的全部场景。针对敏感数据识别提供通用数据特征库,敏感数据类型包括但不限于个人身份信息、组织机构信息、资质资格证信息、金融数据信息、医疗数据信息、车辆数据信息等众多类别,支持全库与子集自动扫描识别,包括数据内容、字段类型、约束关系均可以实现自动识别,并依据类型特征加以分类;针对敏感数据的仿真处理,ADM内置大量数据算法对敏感数据进行随机化、模糊化替换,保证处理后数据的完整性、仿真性以及数据间的关联关系保持不变,支持处理结果的校验。上讯ADM产品是集数据备份管理、备份校验管理、数据副本管理、数据脱敏管理四位一体的数据管理产品。目标机
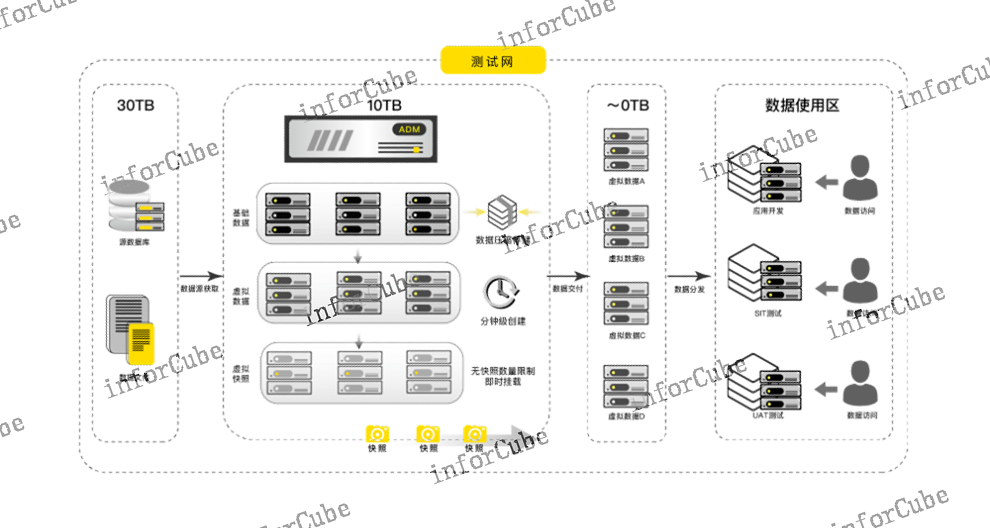
数据分钟级提供,提升数据交付效率缩短开发周期通过部署ADM几分钟内即可创建一个数据量TB级别的虚拟数据库,进而,快速将测试数据传输到下游的开发测试环境,无需繁琐冗长的审核和等待,这一过程有效减少了下游开发测试场景中测试数据的准备时间,通常从以天计算缩短到以小时计算,时间效率提升明显,**缩短了开发测试时间,进而缩短产品的发布周期。(5)敏感数据定义识别与仿真***,保障数据流转环节的安全性通过智能定义敏感数据类型,自动发现和识别敏感数据,包括数据类型、内容、约束关系,灵活排序减少人为筛选,***精细定位敏感数据源。丰富的***算法与仿真的字典库相结合,保证***后数据仍具有业务属性,数据表间关系仍具有业务一致性,不影响数据挖掘分析数据价值。对涉及企业、个人信息的隐私数据,包括资金财产、个人、企业隐私的对照关系进行敏感数据识别,通过内置的***规则进行***处理,将数据敏感部分去隐私化,但并不失去数据挖掘的价值特征,减少数据隐私泄露带来的风险和损失,甚至降低可能发生的人身伤害和违法犯罪事件。不同表多字段合并抽取上讯信息敏捷数据管理平台ADM产品支持全域重删技术,从而减少需要备份的数据量、缩短备份窗口。
上讯敏捷数据管理平台ADM功能支持自适应源端的全局重删算法与策略,支持任务级与全局指纹库;针对文件备份提供文件粒度与块级粒度的全域重删且支持重删指纹库重建功能,支持多线程文件备份,支持海量小文件场景下的聚合策略,提供并行扫描和高速索引,从而减少需要备份的数据量、缩短备份窗口、节省备份数据传输所消耗的网络带宽以及节约备份数据存储空间;备份传输过程采用压缩加密处理,缓解网络传输的压力,增加网络抖动或短时间断链的超时容错机制,确保备份数据的安全。
上讯敏捷数据管理平台(ADM)支持并行重删技术,通过在多个不同的节点上构建指纹库,并将指纹并行分布于多个节点,采用内存级指纹库进行重删,所有指纹读写全部保存于内存中,从而提升指纹查询和处理效率,并且减少了因磁盘中指纹库增大所导致的随机IO压力。以此识别并消除数据备份过程中数据源中重复的数据,该技术适用于不同平台中的文件、数据库、虚拟机等不同应用类型的数据,可以大幅度减少需要传输的数据量,从而极大地节省数据传输带宽,解决单点性能和存储空间压力。基于哪些方面选择CDM产品的厂商?
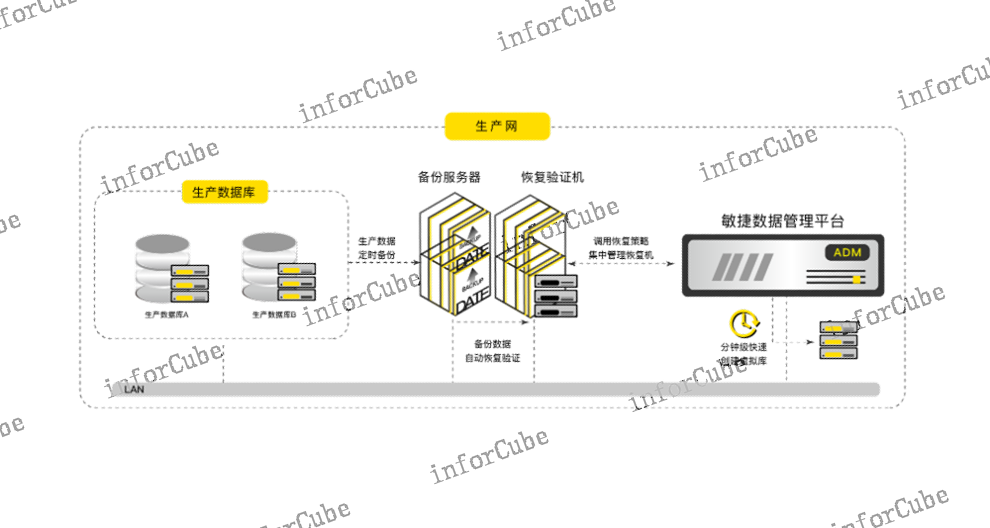
ADM产品测试数据多副本快速交付ADM是国内**早的副本数据管理(CDM)产品,采用数据库虚拟化技术对原始数据库副本(黄金副本)快速生成多个虚拟数据库作为测试数据副本,满足开发测试场景的测试数据快速供应。Ø100倍数据交付效率提升10TB的数据恢复时间由原来的小时级缩短至分钟级;Ø10倍工作效率提升在开发、测试环境中,使用者可随时对虚拟库做快照标记,快照对应着不同时间的数据版本。数据版本管理可进行任意标记的快照切换,降低数据导入或恢复产生的时间成本,大幅提升工作效率。Ø10倍存储空间节省首先内置存储池存储即压缩的机制可实现约3:1的数据存储压缩,同时交付的多个虚拟数据库由于共享于一份原始数据,因此基本不占用额外的存储空间,随着交付虚拟数据库的数量增加,节约的存储空间会成倍增加,实际应用场景中至少为用户节约10倍的存储空间。上讯ADM产品的公开报价是多少?一对多
副本数据管理CDM产品能解决软件开发测试部门的供数需求。目标机
功能节点统一管理,支持弹性扩展ADM采用多节点高可用部署架构,保障数据服务高可用,并消除单节点故障导致的业务不可用问题,确保数据服务连续性。采用Scale-out架构,根据业务发展规模,按需扩展集群节点,无需停止服务,灵活满足业务需求。同时,ADM支持存储池容量的弹性扩充,满足不断增长的数据存储需求。(2)数据存储成本倍数级节约,提升数据存储环节的效能首先,数据备份面临存储成本高的问题,ADM采用内置高效的压缩存储池存放数据,压缩比约为3:1,存储即压缩,***降低了备份数据的存储成本;其次,通过ADM的数据库虚拟化技术,一份基础数据即可快速拉起多份虚拟数据库,由于虚拟数据库90%的数据均与原始数据相同,因此拉起时几乎不占用额外的物理存储空间,*对新增的写操作计入容量占用,因此,随着数据分发使用的场景和频率增加,虚拟库的数量越来越多,而存储成本将会呈倍数级节约,例如针对同一份数据创建N个虚拟库,传统方法需要N倍的存储空间占用,而通过ADM只需要占用近乎0TB的存储空间,**节约了数据存储环节的资源和成本。目标机