约束信息自动发现
ADM平台具备根据管理人员、测试需求等内容的不同进行分组划分的功能,将数据进行分组管理,从下游测试数据管理的源头管控数据资源的类别,做到从源头划分类别,使下游测试数据管理形成上游数据源----中游数据中转----下游数据目标的闭环式数据使用流程,规范化的数据流程使数据管理者成为数据的负责人,自动化的资源管理也更有效地为金融行业用户提供安全的数据管理方案。同时,ADM提供对数据流转的树状拓扑结构图,可详细了解数据的来源、所属存储池、挂载的测试服务器,以及数据快照的层级关系,方便对系统全局的数据使用结构进行预览,通过可视化的结构拓扑图,帮助用户了解下游测试网中测试数据的归属关系,完善数据流转路径,优化数据资源的合理分配,可视化功能的动态展示将助力企业向着智能化数据安全治理的方向转型。数据安全领域的CDM是指拷贝数据管理。约束信息自动发现
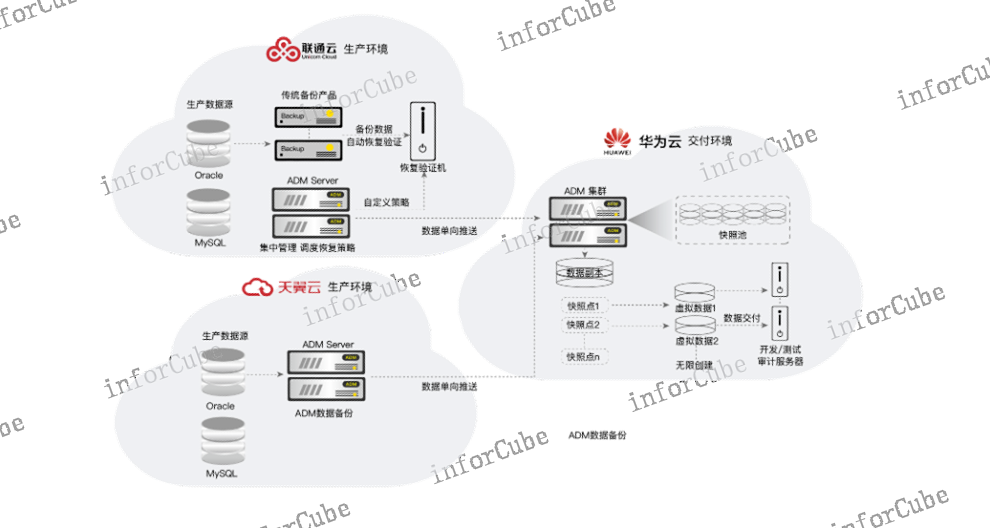
上讯敏捷数据管理平台(Agile Data Management)简称ADM,是采用基于CDM架构的数据库虚拟化等**技术,为企业上中下游数据的备份恢复、数据验证、安全***、分发交付提供的面向数据全生命周期的安全管理解决方案。该产品通过自动化流程任务编排的方式实现了数据使用的成本控制、版本管理与开发利用,充分发挥了备份数据的潜在价值。实现生产数据备份恢复与异地容灾、备份数据自动化恢复与有效性验证、测试数据多副本快速交付、数据安全***。
约束信息自动发现哪个产品支持数据进行敏感处理时的抽取组合?
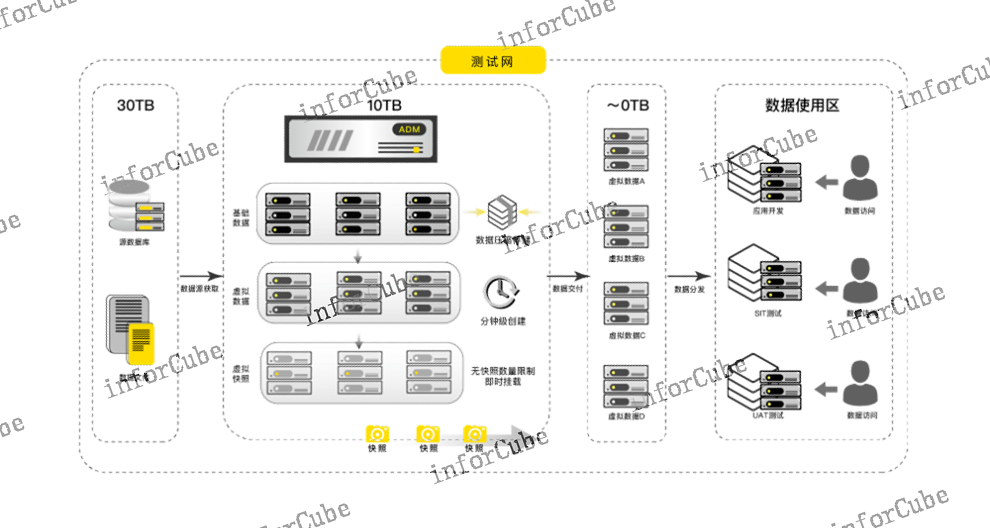
随着信息化程度的不断深入,数据作为企业的资产越来越被重视,虚拟化、云化的不断应用,带来了业务系统及数据的增长,大数据在这种环境中也有了发展和应用。新技术的不断创新与应用,促使着数据不断的被拷贝使用,如何能更好的使用这些数据,如何更好的管理越来越多的拷贝数据,如何能节省新需求下的存储空间,这些都成了当下亟待解决的问题。信息化时代,“数据”的应用较为频繁,海量数据的组成中,备份数据占有很大比例,而这些备份数据在没有发生故障时往往是被搁置不用的,被称为“暗数据”。而对业务数据的分析、统计、运维等操作都会直接作用在业务服务器,如此将会对业务性能产生影响,不利于业务系统的高效使用。如何做到解放业务系统,使其专注于业务处理上,也是IT管理者需要考虑的另一个现实问题。
上讯敏捷数据管理平台(ADM)既可以封装在敏捷数据管理流程的中间环节,也可以单独作为敏感数据处理的抽取平台,两种模式满足了当前用户对数据处理的全部需求。 提供系统用户角色权限的配置管理,负责系统角色用户功能的划分,操作权限的分配,负责处理任务向上级的申请,上级用户负责审批、转发、会签或驳回以及复核工作的需求。当前系统内置丰富的算法,具备广义的通用型规则,包括字符替换、随机生成、截短、加权生成、加密等;支持保留原有数据含义的仿真型规则,支持中文字典库与编码字典库,保证姓名、身份证号、证件号、地址、组织机构代码等数据的有效性、可用性,算法经优化已处理超长字符截断和重复数据的问题。上讯ADM产品通过虚拟数据秒级分发功能实现测试数据的同时在线交付,缩短了数据交付的时间。
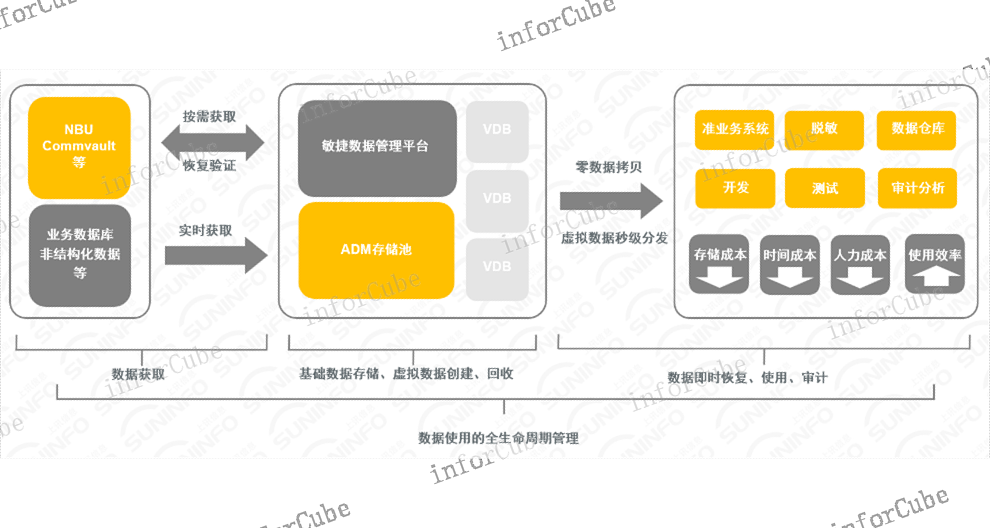
上讯敏捷数据管理平台(ADM)支持重复数据删除技术,在典型的重复数据删除技术中,根据不同的数据备份场景选择适合的重删策略与粒度方案。在确定重删策略与粒度后,会根据输入侧不同粒度(卷级、文件级、块级)的数据采取不同的数据切分策略,并依据任务级与全局指纹库提供自适应源端的全局重删算法与策略,当前支持源端块级、文件级重删和并行重删技术。源端重删是采用基于内容的可变长数据切分算法,通过对数据块进行哈希算法的标记,即指纹(Fingerprint),在指纹库中寻找相同的指纹。如果存在相同指纹,则表示已保存了相同的数据块,ADM则不再保存此数据块,而是引用已存在的数据块,从而节省更多的备份空间。该算法还可以智能识别已修改的数据和未修改的数据,从而避免因修改数据位移而导致的未修改数据切分到新数据块中的问题,较大限度地提升重删性能和重删率,为避免数据备份过程中冗余网络传输与存储开销,在源端设置粗粒度前置数据校验可以明显缩小备份传输过程中的数据冗余,目的在于不备份任意一个冗余数据。数据备份产品关注数据备份,上讯敏捷数据管理平台ADM产品能用于数据的备份与快速恢复验证。操作权限共享
敏捷数据管理平台ADM产品数据信创产品,实现了国产数据库的备份与国产操作系统的兼容。约束信息自动发现
功能节点统一管理,支持弹性扩展ADM采用多节点高可用部署架构,保障数据服务高可用,并消除单节点故障导致的业务不可用问题,确保数据服务连续性。采用Scale-out架构,根据业务发展规模,按需扩展集群节点,无需停止服务,灵活满足业务需求。同时,ADM支持存储池容量的弹性扩充,满足不断增长的数据存储需求。(2)数据存储成本倍数级节约,提升数据存储环节的效能首先,数据备份面临存储成本高的问题,ADM采用内置高效的压缩存储池存放数据,压缩比约为3:1,存储即压缩,***降低了备份数据的存储成本;其次,通过ADM的数据库虚拟化技术,一份基础数据即可快速拉起多份虚拟数据库,由于虚拟数据库90%的数据均与原始数据相同,因此拉起时几乎不占用额外的物理存储空间,*对新增的写操作计入容量占用,因此,随着数据分发使用的场景和频率增加,虚拟库的数量越来越多,而存储成本将会呈倍数级节约,例如针对同一份数据创建N个虚拟库,传统方法需要N倍的存储空间占用,而通过ADM只需要占用近乎0TB的存储空间,**节约了数据存储环节的资源和成本。约束信息自动发现